

Exploring Aurora Serverless v2: Architecture, Scaling, High Availability, and Failover


Amazon Aurora Serverless is a fully managed, on-demand, auto-scaling relational database service(RDBMS) provided by AWS. It allows users to consume a database in a serverless mode, where the database automatically scales up or down in response to application demand with a simple pay-per-use model. The term serverless w̵h̵i̵c̵h̵ ̵I̵ ̵p̵e̵r̵s̵o̵n̵a̵l̵l̵y̵ ̵d̵o̵ ̵n̵o̵t̵ ̵l̵i̵k̵e̵means there are servers but “you” don’t have to provision and manage.
Aurora Serverless is based on MySQL and PostgreSQL-compatible database engines same as Amazon Aurora.
In this article, we will take a closer look at the architecture of AWS Aurora Serverless, with a focus on its use case, Write and Read scaling capabilities, high availability features, failover mechanisms, and a comparison between version 1 and the latest version.
Use case
Variable workloads: Applications that experience sudden spikes in traffic or workload, such as e-commerce websites during holiday seasons, and sales promotions. For such applications with Aurora Serverless v2, your database automatically scales the capacity to meet the needs of the application’s peak load and scales back down when the surge of activity is over.
Multi-tenant applications: Consider you have a multitenant application with a database-per-tenant approach. Increasing numbers of tenants will demand their own database. With this service, you don’t have to individually manage the database capacity for each application.
Deep Dive
Let’s deep dive into its architecture
Architecture
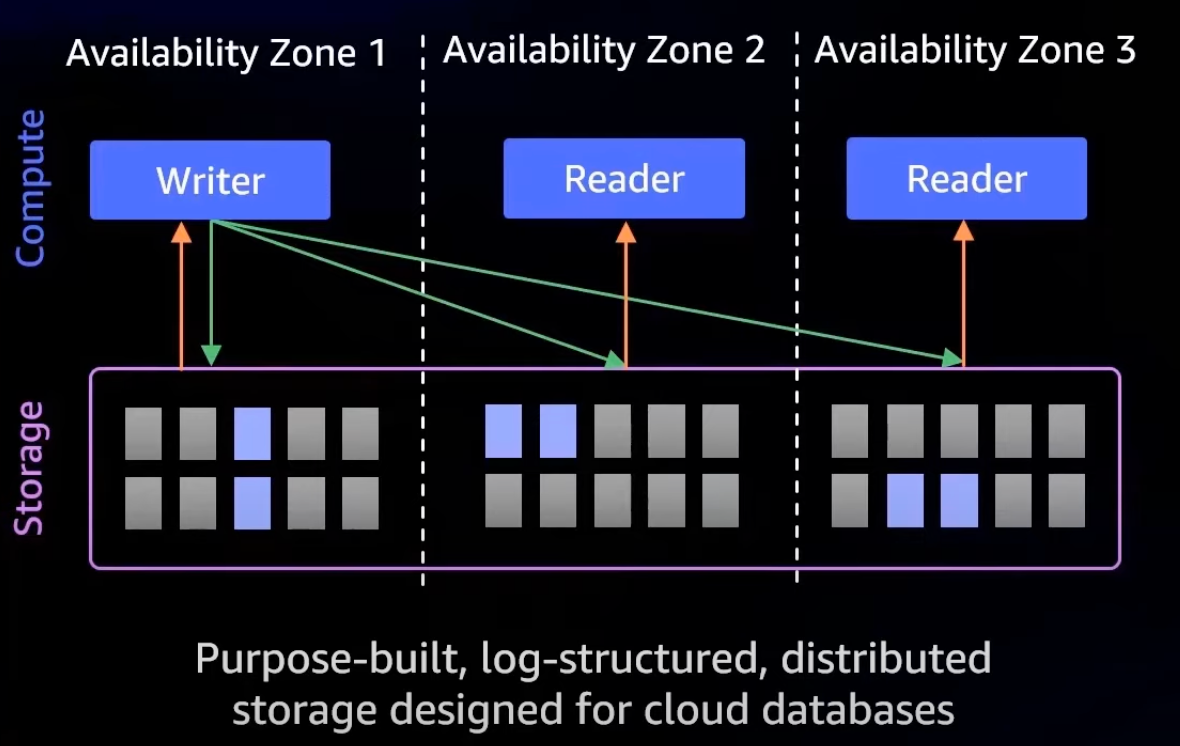
A key architectural feature of Aurora Serverless is the separation of its compute and storage layers as depicted in the above diagram.
Storage: Aurora data is stored in the cluster volume, which is a single, virtual volume that uses solid state drives (SSDs). A cluster volume consists of copies of the data across three Availability Zones(AZs) in a single AWS Region. It stores 6 copies of your data across these 3 AZs. Because the data is automatically replicated across Availability Zones, your data is highly durable with less possibility of data loss. This replication also ensures that your database is more available during a failover. It is because the data copies already exist in the other Availability Zones and continue to serve data requests to the DB instances in your DB cluster. The amount of replication is independent of the number of DB instances in your cluster.
Compute: The compute layer in the Aurora Serverless is responsible for processing queries and transactions on the database. It is decoupled from the storage layer, allowing it to scale independently based on the workload of the database. This means that compute resources can be added or removed dynamically based on demand, ensuring optimal performance and cost efficiency.
The compute capacity for Aurora is called Aurora compute capacity(ACU). A single ACU generally has 2GB RAM and a corresponding CPU. This is a part of the configuration needed to provide with min and max ACU.
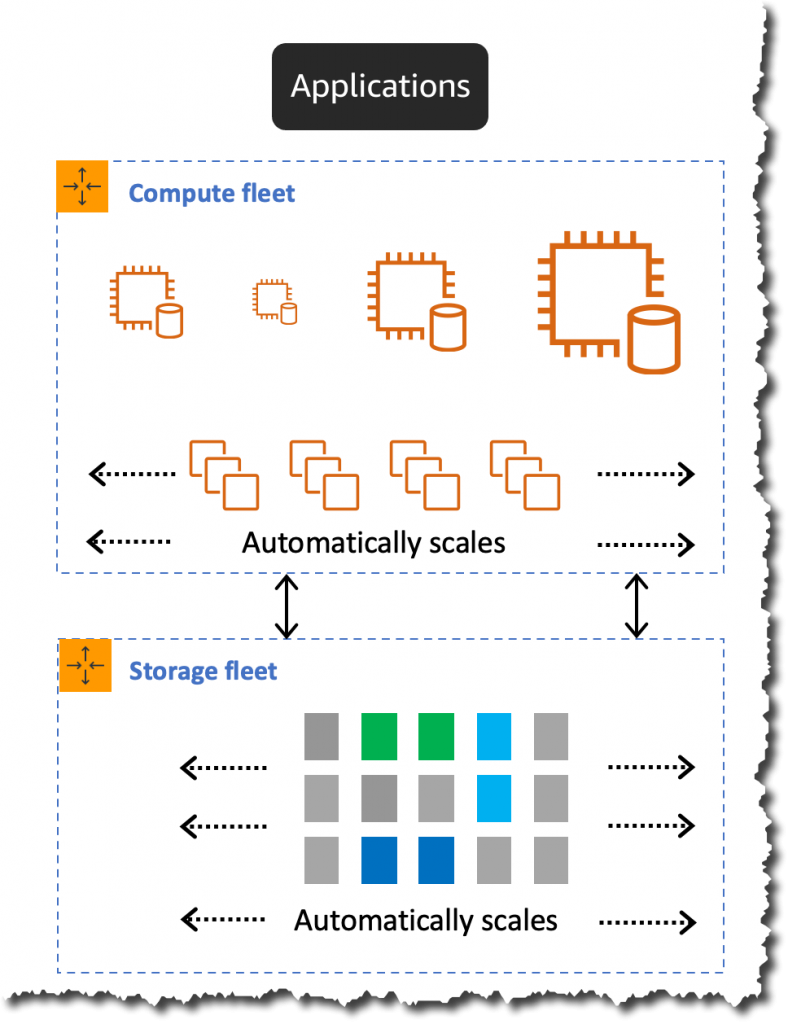
As we discussed the beauty of the architecture is the separation of compute and storage layers allowing both to scale individually.
Let’s discuss more granularly Write and Read scalability from the applications point of view
Write scalability: Writes are scaled by scaling compute capacity of the write node to handle more concurrent transactions. It is done by growing the capacity of the underlying instance in place by adding more CPU and memory resources
Note: When a write operation is performed, it is first written to the write-ahead log (WAL) buffer of the primary instance, which then replicates the write to the storage nodes.
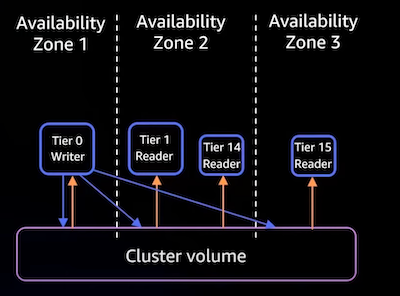
Read Scalability: Aurora Serverless allows you to create up to 15 Aurora Replicas that can serve read traffic, providing additional read throughput and lower latency. Aurora Serverless provides reader endpoints for read replicas that can be used to balance the load among multiple read replicas for read queries.
Rings a bell? I know... You might be wondering if there are chances of stale data being returned from these read replicas due to replication lag.
Well, theoretically yes, Since Aurora is designed with eventual consistency, not strong consistency. But Practically, since Amazon Aurora Replicas share the same data volume as the primary instance in the same AWS Region as discussed under the Storage section, there is virtually no replication lag. We typically observe lag times in the tens of milliseconds.
High Availability and Failover
For High availability, you can configure the Aurora DB cluster as a Multi-AZ DB cluster. A Multi-AZ Aurora DB cluster has to compute capacity available at all times in more than one Availability Zone (AZ). That configuration keeps your database up and running even in case of a significant outage. The read replicas act as a failover point. Aurora performs an automatic failover in case of an issue that affects the writer or even the entire AZ.
Comparison to V1
A few important points involving today’s discussion
More granular scaling in terms of resources for example Aurora V1 allowed scaling by a factor of 2 which means if you have 2 ACUs and need to scale it will scale to 4 or 8 while V2 will scale as many as it wants even a half(0.5) ACU.
Aurora Serverless v1 cluster isn’t a Multi-AZ cluster. So failover takes a longer time and you may expect downtime.
Support seamless scaling against the challenges of V1
Reference(s):
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/CHAP_AuroraOverview.html
https://aws.amazon.com/blogs/database/read-scalability-with-amazon-aurora-serverless-v2/
Your engagements are welcome! I write about my learning of scalable system design concepts. Subscribe for more such articles.