Multitenant Database Designs with PostgreSQL

software engineer with over 10 years of experience designing, developing, and leading enterprise and cloud-native applications. With a specialization in cybersecurity and infosec domains, I have SOAR, IPaaS, and business workflow automation expertise.
Introduction
Multitenancy is an architecture that allows multiple customers, or tenants, to share the same application or database while maintaining their data isolation and security. It is becoming increasingly popular in SaaS applications due to its numerous benefits, including reduced costs, better scalability, and performance. By sharing resources and infrastructure, multitenancy allows for significant cost savings.
In this article, we’ll discuss multitenant database design using PostgreSQL.
Multitenant Database Design Options
There are typically three design strategies to achieve a tenant data separation
A database per tenant
Schema per tenant
Shared table
Now, let’s take a closer look at each of the multitenant database design strategies mentioned above to gain a better understanding of their benefits and limitations.
A database per tenant
A database-per-tenant strategy is a common approach to multitenant database design, where each tenant is assigned a separate database to store all its data.
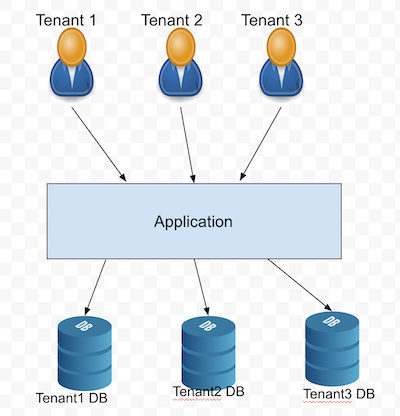
In PostgreSQL, implementing a database-per-tenant strategy is relatively straightforward. The first step is to create a new database for each tenant. This can be done using the CREATE DATABASE command in PostgreSQL. Once the database is created, it can be assigned to the corresponding tenant, who will have full access to the data stored in that database.
Advantage
Strong data isolation and security: Each tenant has its own separate database, providing the highest level of data isolation and security.
Easy to delete tenants without the risk of impacting other tenants
Important for businesses that need to comply with strict regulatory requirements.
No Noisy neighbor problem
Supported by all the databases
Limitations :
Operational and management overhead: One of the biggest challenges of implementing a database-per-tenant strategy is the operational and management overhead. As the number of tenants grows, the number of databases that need to be managed also increases. This can be challenging, particularly in terms of maintenance and backups. Configuring, updating, setting up replication, and backing up each database can be time-consuming. It requires dedicated resources and expertise to ensure that each database is properly managed and maintained.
Higher costs: Running multiple databases is more costly than running a single database with other approaches.
Limited resource sharing: Resources such as CPU, memory, and disk space are not shared between tenants.
With a single PostgreSQL server and multiple databases, there is a risk that some connections may remain underutilized while other tenants are unable to access the database due to a lack of available connections. This can occur when a client creates a connection pool against a specific database. If that connection pool is not fully utilized by a tenant, the unused connections can be tied up, preventing other tenants from accessing the database.
No Cross references: No support for foreign keys into shared data. It’s not possible to create foreign keys that reference shared data across multiple databases.
Shared Data: It’s common to have some data that is shared across all tenants. This could include configuration data or other types of metadata that are used by all tenants. With this approach you have to keep the common data with all the databases and updates in this data has to be synced to all
Metrics data: Complex metrics operations involving multiple tenants can not be easily supported
You Can not use transactions across the tenant.
Schema per tenant
The schema approach involves storing all tenant data in the same database but in different schemas. A schema is a container or logical grouping for database objects such as tables, views, and functions. Each tenant has its own schema which in turn has its tables within the database, which is isolated from the other schemas.

To implement the schema approach, you’ll need to create a new schema for each tenant that you add to the system. You can do this using the CREATE SCHEMA statement:
CREATE SCHEMA tenant1;
This above statement creates a new schema named tenant1 in the current database. You can then create tables and other database objects within the new schema, just like you do with the default schema called "public".
To switch between schemas, you can use the SET search_path statement:
SET search_path TO tenant1, public;
This statement sets the search path to the tenant1 schema, allowing you to access tables within that schema. You can also switch to a different schema with the same command:
SET search_path TO tenant2, public;
Isolation/Security: To implement tenant isolation, you’ll need to ensure that each tenant can only access their own data within the database.
First, you create a role for a particular tenant
# create with default postgresql user
# sudo -u postgres
CREATE ROLE tenant1 LOGIN PASSWORD 'tenant1password';
Create a new schema with ownership
CREATE SCHEMA tenant1data AUTHORIZATION tenant1;
Then, grant privileges to the role on that schema.
GRANT ALL PRIVILEGES ON SCHEMA tenant1data TO tenant1;
This grants the “tenant1” role full permissions (including SELECT, INSERT, UPDATE, DELETE, and more) on the “tenant1data” schema.
Having discussed the schema creation in PGSQL and its security let’s discuss its advantages and limitations
Advantage:
Shared resource utilization contrary to the earlier discussed database per tenant approach
Cross-referencing is possible. You can refer to common data across schema generally kept in the public schema
You still get Strong isolation
simplifies database maintenance and administration
Transactions across tenants can be supported
Extensible — new schema creation for new tenants is very easy
This is best when you have a relatively small number(that’s not small actually) of fairly large(huge data) tenants
Good use of connections as they are against the database not against the tenant
limitations
Physically all data is present at the same location as it is a logical separation of the data.
Might not be a good option if you have a huge number of tenants each with very little data
Not all DBs support this feature
IMO, the schema per tenant is a balanced approach of multitenant design that requires data isolation. Now let’s discuss our final approach to the shared table now
Shared Table Approach
The shared table data approach is another popular multi-tenant database design strategy in PostgreSQL. In this approach, a single database and schema are used for all tenants, and tenant data is stored in shared tables with a tenant identifier column such as tenant_id to ensure data isolation.
CREATE TABLE customers (
id SERIAL PRIMARY KEY,
tenant_id INTEGER NOT NULL,
name TEXT NOT NULL,
email TEXT NOT NULL,
CONSTRAINT fk_customers_tenant FOREIGN KEY (tenant_id) REFERENCES tenants (id)
);
In this example, the customers table has a tenant_id the column that serves as the tenant identifier.
When querying data from the customers table, the query would include a filter based on the tenant_id
SELECT * FROM customers WHERE tenant_id = 1;
Security :
Row-level security (RLS) in PostgreSQL can be used to implement security in this multi-tenancy approach. RLS allows you to restrict access to certain rows in a table based on predefined security policies. After applying the row-level security policy on the shared table with user context, each tenant user would only be able to see their own data without the need to manually pass the tenant_id filter in the query. This is because the policy applies the filter automatically based on the user's context.
You can read more about the implementation of PG row-level security here.
Advantage:
Simple and easy to implement
Transactions, foreign key reference works as it is the same table
Supported by all the database
Disadvantage:
No strong isolation of data
Each query must include a filter based on the tenant identifier column to ensure data isolation. This can result in more complex and potentially slower queries, especially for large datasets.
Any changes made to the shared schema or tables must be carefully managed to ensure that they do not impact data for other tenants.
That’s it, we explored the various data separation strategies for implementing a multitenant database in general and specifically in PostgreSQL.
I have written this article, having decided to go with the Schema per tenant approach for our application. As no one approach is perfect and there is always some trade-off involved in designs, I would love to hear from you about your experiences with any of these strategies and welcome your engagement in the comments section.



